


VIRTOOAIR: VIrtual Reality TOOlbox for Avatar Intelligent Reconstruction
Concept
The project focuses on designing and developing a Deep Learning framework for improved avatar representations in immersive collaborative virtual environments. The proposed infrastructure will be built on a modular architecture tackling: a) a predictive avatar tracking module; b) an inverse kinematic learning module; c) an efficient data representation and compression module.
In order to perform precise predictive tracking of the body without using a camera motion capture system we need proper calibration data of the 18 degrees-of-freedom provided by the VR devices, namely the HMD and the two hand controllers. Such a calibration procedure involves the mathematical modelling of a complex geometrical setup. As a first component of VIRTOOAIR we propose a novel position calibration method using deep artificial neural networks, as depicted in the next figure.
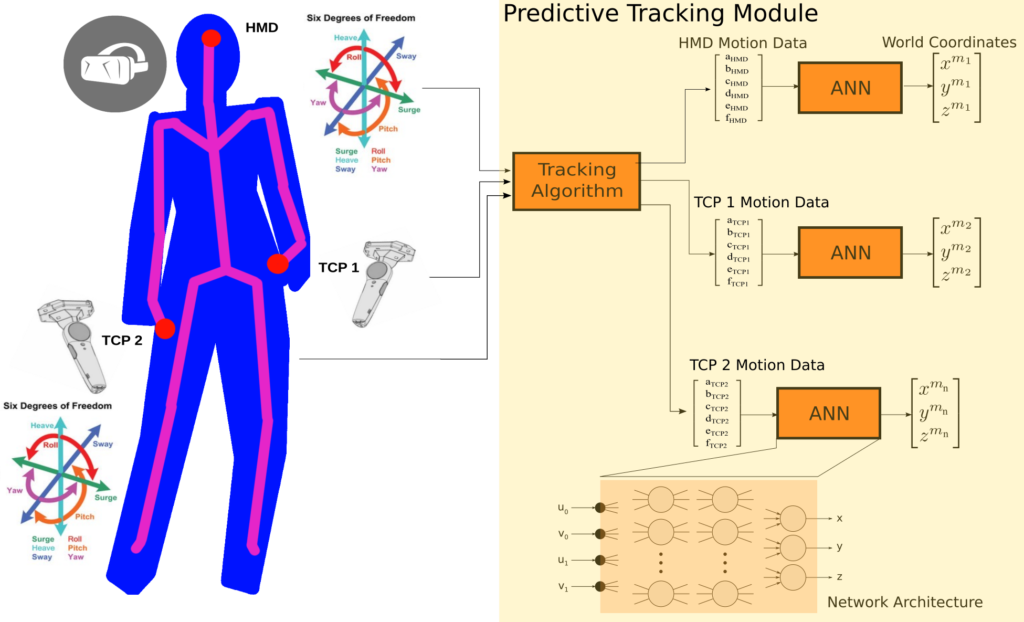
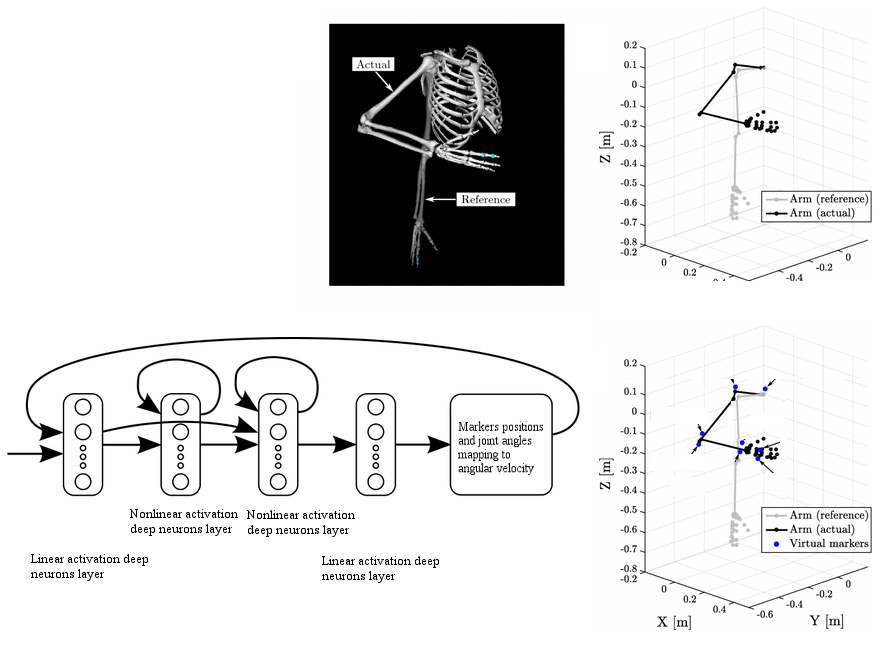
The second component in the VIRTOOAIR toolbox is the inverse kinematics learner, generically described in the following diagram. The problem of learning of inverse kinematics in VR avatars interactions is useful when the kinematics of the head, body or controllers are not accurately available, when Cartesian information is not available from camera coordinates, or when the computation complexity of analytical solutions becomes too high.
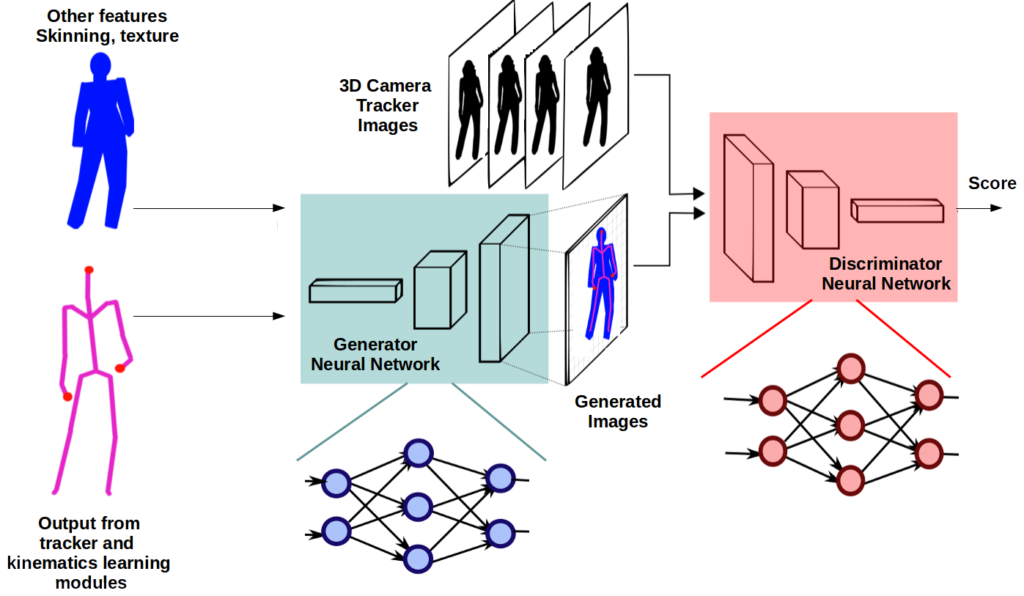
Data and bandwidth constraints are substantial in remote VR environments. However, such problems can be solved through compression techniques and network topologies advances. VIRTOOAIR proposes to tackle this problem through its third component, a neural network data representation (compression and reconstruction) module, described in the following diagram.
The project aims at integrating such systems in various technical applications targeting the biomedical field, for rehabilitation and remote assistance.
Preliminary results
VR motion reconstruction based on a VR tracking system and a single RGB camera
Our preliminary results demonstrate the advantages of our system’s avatar pose reconstruction. This is mainly determined by the use of a powerful learning system, which offers significantly better results than existing heuristic solutions for inverse kinematics. Our system supports the paradigm shift towards learning systems capable to track full-body avatars inside Virtual Reality without the need of expensive external tracking hardware. The following figure shows preliminary results of our proposed reconstruction system.

VIRTOOAIR Visualization
For the upper body reconstruction, the semantically higher VR tracking system data is used. The lower body parts are reconstructed using state-of-the-art deep learning mechanism which allows pose recovery in an end-to-end manner. The system can be split in five different parts: tracking data acquisition, inverse kinematic regression, image processing, end-to-end recovery and visualization.

VIRTOOAIR Architecture
First test results with the described system show that it is capable to recovery human motion inside Virtual Reality and outperforms existing Inverse Kinematic solvers for the upper body joint configuration. The following table shows the mean per joint position error (MPJPE) and the mean per joint rotation error (MPJRE):
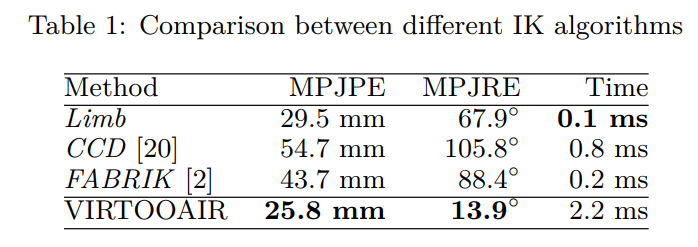
VIRTOOAIR Preliminary evaluation
With the proposed system we introduced a novel, inexpensive approach to achieve high-fidelity multimodal motion capturing and avatar representation in VR. By fusing an inverse kinematics learning module for precise upper-body motion reconstruction, with single RGB camera input for lower-body estimation the system obtains a rich representation of human motion inside VR. The learning capabilities allow natural pose regression with cheap and affordable marker-less motion capturing hardware. In the future we will further extend VIRTOOAIR and combine the gained knowledge about learned IK for upper body reconstruction with the lower-body end-to-end recovery framework for a holistic motion reconstruction framework which fuses the higher semantic VR tracking data with the RGB image stream.
Our first results show that deep learning has major advantages compared to traditional computer graphic techniques for avatar reconstruction. Based on our first successes in learning the Inverse Kinematics (IK) with a neural network we will further extend VIRTOOAIR to a holistic system which fuses the RGB camera stream with the precise tracking data of the VR tracking system. One of the challenges is that a huge amount of training data is required. Available motion databases are limited in the sense as that: only a small number of people are captured, the shape of people is not measured and none of the users wears a head mounted display (HMD). To tackle these limitations we will use a game engine based data generator and train a neural network with artificially created images. With this technique we expect that a neural network for human pose and shape tracking can be trained without the need of very costly motion capturing systems and a huge amount of users preforming different motions.
VR motion tracking and prediction based on a VR tracking system and deep recurrent neural networks (RNN)
Our initial studies shown that Motion Capturing Systems suffer from several problems, such as latencies between body-movements and the calculations of the changed position or loss of the optical contact of the tracking system and the tracking devices. To tackle these problems we designed a neural tracking network system. This system uses LSTM (Long-Short Term Memory) Cells to predict the future position and rotation of the tracking devices based on previous data-points. As LSTMs are capable of memorizing, forgetting and ignoring input over time values, they are a powerful tool to handle time sequences with dynamic length and long-term dependencies, as human motions are.
![]()
VIRTOOAIR Prediction and Tracking NetCurrently this predictive tracking system is capable of predicting the next position of the device within a mean error of 1.3 cm (see blue trace). As metric to evaluate the network, the euclidean distance, e.g. the distance in the three dimensional space between prediction and ground truth, is used. For a multi-step prediction a recursive approach is used. Here the prediction of the network itself is used as the next input (see green trace). The assumption, that the prediction of the further movement path is done by the feedback-loop, is insufficient as it assumes a limited order of time-lags fed into the network while training it.
With a poor chosen order of time-lags, there may not be enough information of the past to predict far ahead into the future, as the order of Truncated Back-propagation Through Time (i.e. TBPTT – training approach for the LSTM) is correlated with the order of time-lags. Using a too small order of the TBPTT means that the error is not propagated far enough into the past and this induces a problem in network’s learning process for the long-term-dependencies. In this case the error back-propagation stops before reaching the horizon and thus makes it unfeasible to do long-term predictions.![]()
VIRTOOAIR Prediction and Tracking Performance