Neuromorphic Vision Processing for Autonomous Electric Driving
Scope
The current research project aims at exploring object detection algorithms using a novel neuromorphic vision sensor with deep learning neural networks for autonomous electric cars. More precisely, this work will be conducted with the Schanzer Racing Electric (SRE) team at the Technical University of Ingolstadt. SRE is a team of around 80 students, that design, develop and manufacture an all-electric racing car every year to compete in Formula Student Electric. The use of neuromorphic vision sensors together with deep neural networks for object detection is the innovation that the project proposes.We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan Xp GPU used for this research.
Context
Autonomous driving is a highly discussed topic, but in order to operate autonomously, the car needs to sense its environment. Vision provides the most informative and structured modality capable of grounding perception in autonomous vehicles. In the last decades, classical computer vision algorithms were used to not only locate relevant objects in the scene, but also to classify them. But in recent years, major improvements were reached when first deep learning object detectors were developed.
In general, such object detectors use a convolutional feature extractor as their basis. Due to the multitude of feature extraction algorithms, there are numerous combinations of feature extractor and object detectors, which influences a system designer’s approach. One of the most interesting niches is the analysis of traffic scenarios. Such scenarios require fast computation of features and classification for decision making.
Our approach to object detection, recognition and decision making aims at “going away from frames”. Instead of using traditional RGB cameras we aim at utilizing dynamic vision sensors (DVS – https://inivation.com/dvs/). Dynamic vision sensors mimic basic characteristics of human visual processing (i.e. neuromorphic vision) and have created a new paradigm in vision research.
Similar to photoreceptors in the human retina, a single DVS pixel (receptor) can generate events in response to a change of detected illumination. Events encode dynamic features of the scene, e.g. moving objects, using a spatio-temporal set of events. Since DVS sensors drastically reduce redundant pixels (e.g. static background features) and encode objects in a frame-less fashion with high temporal resolution (about 1 μs), it is well suited for fast motion analyses and tracking. DVS are capable of operating in uncontrolled environments with varying lighting conditions because of their high dynamic range of operation (120 dB).
As traffic situations yield fast detection and precise estimation, we plan to use such an event-based visual representation together with two convolutional networks proved to be suitable for the task. The two algorithms we plan to explore are the Single Shot Multibox Detector (SSMD), which got popular for its fast computation speed, and the Faster Region-Based Convolutional Neural Network (Faster RCNN), which is known to be a slow but performant detector.
Motivation
The project tries to set a fundamental exploratory work, both in terms of sensory data for environment perception and also neural network architectures for the considered task. The experiments aim at evaluating also the points where better accuracy can only be obtained by sacrificing computation time. The two architecture we chose are opposite. The first one is the SSMD network with Inception V2 as a feature extractor. This network has a low computation time with acceptable accuracy. The correspondent network is the Faster RCNN with ResNet-101 as its feature extractor. Its accuracy is one of the highest, whereas the computation time is relatively slow.
Whereas features are common for frame-based computer vision problems, no solution exists yet to determine unique features in event streams. This is the first step towards more complex algorithms operating on the sparse event-stream. The possibility to create unique filter responses gives rise to the notion of temporal features. This opens the exploratory work we envision in this project, to investigate the use of SSMD and Faster RCNN networks using event-based input in a natively parallel processing pipeline.
Current state (November 2018)
Progress overview
In the progress of developing deep neural network structures (i.e. the SSMD and Faster RCNN) that operate on the event based features to deal with the stereo problem the team investigated first how to represent the event-based visual information to be fed to the deep neural networks. The team developed a series of neural networks for object detection of the lane markings. Not only the networks could identify the type of object (object classification), but more importantly gain real-time data about the localization of the given object itself (object localization). By collecting and labeling a large training dataset of objects, the team implemented various neuronal networks providing us the needed accuracy for safely maneuvering our car. The networks used pre-trained weights from an already existing network for speeding up the training process significantly. The employed methods tapped into transfer learning, before nVidia actually releasing the Transfer Learning Toolkit. The team employed pre-trained deep learning models such as ResNet-10, ResNet-18, ResNet-50, GoogLeNet, VGG-16 and VGG-19 as a basis for adapting to their custom dataset. These networks could incrementally retrain the model with the help of the Transfer Learning for both object detection and image classification use cases. The TitanX GPU granted through the Nvidia GPU Grant program allowed the team to train the deep networks.
Development stages
In the first development phases, the team used nVidia’s Drivenet without modification. The input size with 1248 to 384 pixels was found suitable for our application. A screenshot with this image size used for training can be seen in the following.
The team was further able to optimize the network input size for the autonomous electric car application by adjusting the first layers of the Detectnet architecture and thus using the whole camera image width of 1900 pixels. While this step lowered the computational performance of inference at first, the team made great improvements in detection speed using a TensorRT optimized version of the net. The comparison of different network architectures vs. their computational performance can be seen in the following. Measurements were taken on a Nvidia Drive PX2 platform.

Using the predicted bounding boxes of this network, the Nvidia Driveworks API and a triangulation based localization approach, the team was able to predict 2D position of the road markings with +- 5% accuracy. To further increase the system’s debugging possibilities and gain experience with different neural network models, the team took a darknet approach into consideration. More precisely, the team made experiments with yoloV3 as well as tiny yoloV3, which allowed for an easy implementation into the existing ROS environment. Yolo allows straightforward adaptation of network architecture. Furthermore, varying input image sizes can be used without the need to retrain the whole network, which makes it very flexible for ongoing development. The used yoloV3 network architecture is shown in the following diagram.

Yolo utilizes the great power of CUDA and CUDNN to speed up training and inference, but is also highly portable to various systems using GPU or CPU resources. Again, the team is very thankful given the TitanX GPU which allowed us to execute the network training and inference testing. The team is currently experimenting with the amount and design of convolution and pooling layers. As the objects to detect are rather simple, it should be sufficient to use a small amount of convolutional filters opposing to the original yolonet architecture. Wile the original yoloV3 uses 173.588 Bflops per network execution, reducing the amount of layers results in 148.475 respectively 21.883 Bflops per iteration. These networks are not fully trained yet, but promise to deliver satisfying accuracy with much less inference time.
Next steps
In the next steps, having classification and recognition tackled, the team will focus on designing a network architecture able to take into account temporal aspects of the stereo-events from the neuromorphic camera in addition to existing physical constraints such as cross-disparity uniqueness and within-disparity smoothness. The network’s input includes the retinal location of a single event (pixel coordinates) and the time at which it has been detected. Consequently such non-linear processing, with good inference timing, offered by the yoloV3 and Detectnet can further facilitate a mechanism to extract a global spatio-temporal correlation for input events. Knowing the disparity of a moving object in the car’s vision sensors’ field of view, the team will further analyse the accuracy and the detection rate of the proposed algorithm.
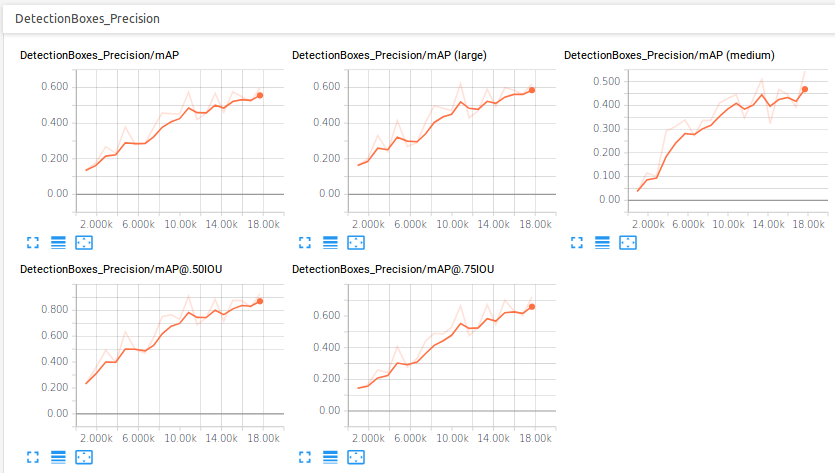
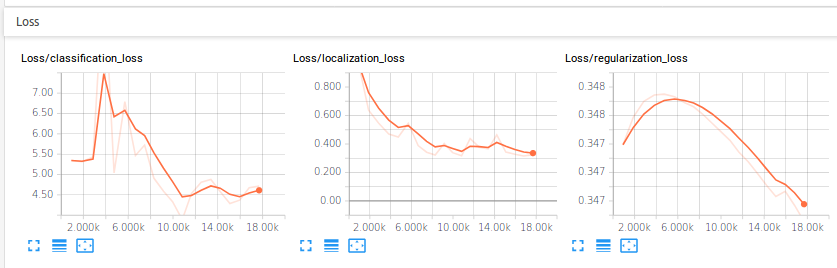
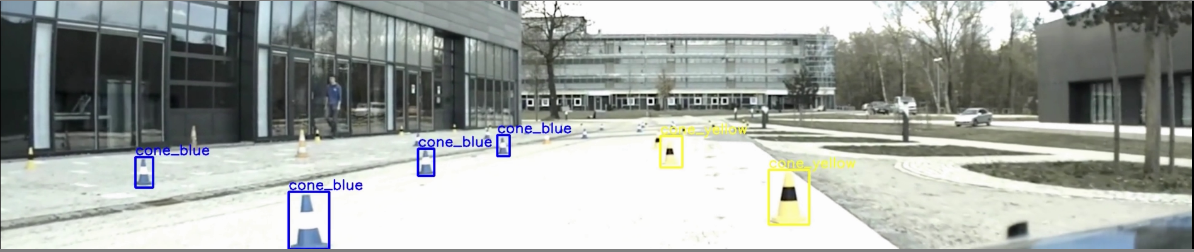
Preliminary results ( July 2018)
The initial step was carried in training a single shot detector (mobilenet) for the cone detection, a stage in the preparation the Formula Electric competition. Experiments were carried on an nVidia GTX1080Ti GPU using TensorRT. The performance evaluation is shown in the following diagrams.