2017年11月22日
If you are interested in exploring AI for Biomedical Applications with us, and writing your Bachelor or Master Thesis please contact Dr Cristian Axenie (cristian.axenie@audi-konfuzius-institut-ingolstadt.de) or Prof. Thomas Grauschopf (thomas.grauschopf@thi.de).
NEW TOPICS
Control Algorithms for Adaptive Chemotherapy Regimens
Problem Description
Chemotherapy is a widely accepted method for tumour treatment. A medical doctor usually treats patients periodically with an amount of drug according to medical oncology guidelines. At the moment chemotherapy is much influenced by the “dose-dense” paradigm, advocating maximally possible dose density early in treatment. This paradigm is based on a controversial mathematical model, assuming an exponential tumour growth law. Alternatively, it has been suggested that for maximizing the efficacy/toxicity ratio in cancer chemotherapy, the inter-dosing intervals should be determined and controlled on a per-patient basis. In order to achieve this, simulation comes into play as a powerful tool to test and validate novel chemotherapy regimens. Simulation allows us to realistically model cancer mechano-biology while maintaining the resolution power which makes it time and cost-effective. By modelling and simulating the growth of a tumour, clinicians can better understand how a tumour may develop and progress. Cancer researchers could use however such models in the future to improve the outcome of pertinent therapeutic procedures using adaptive control algorithms. From classical linear control algorithms and up to model-free deep reinforcement learning approaches, finding solutions for personalized chemotherapy regimens is still an open problem. The optimal treatment schedule and drug dose vary according to the stage of the tumour, the weight of the patient, the white blood cell levels (immune cells), concurrent illness and age of the patient. The goal of the thesis project is to establish initial steps that evaluate classical and intelligent control algorithms towards a personalized chemotherapy regimen leading to increased longevity and quality of life of a patient.
Tasks
Get familiar with tumour growth and chemotherapy drug models.
Get familiar with typical control algorithms used in chemotherapy.
Get familiar with BioDynaMo simulator.
Implement and simulate simple control loops for drug administration for tumour models.
Evaluate and analyse the control algorithms’ performance.
Implement an interface to BioDynaMo to control a simulated evolving tumour model.
Skills
Strong programming experience (Python), mathematical modelling skills, and hands-on ML libraries.
Preferred field of study
BA/MA Computer Science, BA/MA Electrical Engineering
Contact person
Dr Cristian Axenie – cristian.axenie@audi-konfuzius-institut-ingolstadt.de
Prof. Thomas Grauschopf – thomas.grauschopf@thi.de
Predicting Chemotherapy-induced Polyneuropathy using Machine Learning
Problem Description
Problem description Chemotherapy-induced polyneuropathy (CIPN) affects more than two-thirds of adults with invasive cancer who receive adjuvant chemotherapies. CIPN occurs from exposure to neurotoxic chemotherapeutics that damage peripheral nerves. Patients with CIPN exhibit fatigue and muscle weakness, which decreases the overall quality of life, and severe symptoms can alter even autonomic processes (e.g., breathing and heart rate); thereby affecting the potential curative effects of chemotherapy. The incidence of peripheral neuropathy differs significantly across chemotherapeutic agents and the type of cancer. For instance, breast cancer has become the type of cancer that has the best long-term prognosis, yet many survivors suffer from CIPN. CIPN is a high priority for patients in thinking about treatment choice and survivorship care planning. But, the relative importance of CIPN for the patient and provider decision-making varies by patient characteristics (e.g., age, cancer stage). Although there are no publicly available, validated systems to predict the development of CIPN in individual patients, the risk of developing severe and chronic CIPN can be predicted with a high degree of accuracy using available patient clinical data, drug characteristics, and machine learning methods. The goal of this thesis project is to develop a clinical decision-support system to predict CIPN development and evaluate correlations and predictors in breast cancer clinical data. Using open-source clinical datasets, data analysis, and machine learning you will develop and validate predictive models to quantify the risk of developing CIPN and deploy a standalone system that will improve cancer treatment and survivorship care planning. The system will be tested by our clinical partners and could be validated also on new, real clinical data.
Tasks
Get familiar with breast cancer clinical data from Simulacrum Cancer Database.
Exploratory data analysis and visualization.
Feature selection, feature engineering, data fusion relevant for CIPN prediction.
Develop suitable machine learning models for CIPN prediction.
Evaluate and analyse the machine learning models performance.
Develop a web-based application to make CIPN predictions for new patients.
Skills
Strong programming experience (Python & Web/JS), statistics skills, hands-on ML libraries.
Preferred field of study
BA/MA Computer Science, BA/MA Electrical Engineering
Contact person
Dr Cristian Axenie – cristian.axenie@audi-konfuzius-institut-ingolstadt.de
Prof. Thomas Grauschopf – thomas.grauschopf@thi.de
Real-time face-swap algorithms
Problem Description
The basic idea of face-swapping is to swap one person’s face with another person’s face. The so-called DeepFake algorithm was introduced for the first time at the end of 2017 and caused a sensation especially on the internet. Using the open source program, you can share a person’s face with another person’s face in a video stream. However, DeepFake requires a lot of processing power and can not be done in real-time. For many application scenarios, however, a real-time capable process would be desirable. The aim of this work is to investigate which alternative approaches are already available for live face swapping and in which the different procedures differ in detail.
Tasks
• Familiarize yourself with different face-swap techniques using Deep Learning.
• Evaluate and compare existing approaches.
Skills
General programming knowledge. Desirable would be first experiences with the programming language Python.
Preferred field of study
BA / MA Computer Science, BA / MA Electrical Engineering, BA / MA Mechatronics
Contact person
Prof. Thomas Grauschopf – thomas.grauschopf@thi.de
Development of a virtual camera driver
Problem description
Currently, there are many different video chat or video telephony programs. These use the driver of a connected RGB camera for reading out a video signal. The aim of this work is to write a virtual camera driver that is recognized by the video chat programs such as Skype as a RGB camera connected to the PC. By prior tapping of the video stream of the camera connected to the PC and the subsequent forwarding to the virtual camera driver an image processing pipeline is to be created, which allows the free manipulation of videos (i.e. image processing). The work should also be about evaluating the software solution in terms of performance.
Tasks
- Development of software for reading a RGB camera stream using OpenCV.
- Apply simple real-time image processing algorithms to the video stream.
- Development of a virtual camera driver to distribute the processed video to other programs such as Skype.
- Evaluate performance (e.g., latency and CPU utilization) of the program.
Skills:
Good programming skills in the languages C and C ++. It would be desirable to have some initial experience in the field of driver programming and in dealing with the OpenCV image processing library.
Preferred field of study
BA / MA Computer Science, BA / MA Electrical Engineering, BA / MA Mechatronics
Contact person
Prof. Thomas Grauschopf – thomas.grauschopf@thi.de
Event-based Attention Network for Object Tracking
Problem description
Visual attention is the mechanism the nervous system uses to highlight specific locations, objects or features within the visual field. This can be accomplished by making an eye movement (overt attention) or by increased processing of visual information in neurons representing more peripheral regions of the visual field (covert attention). In this project we propose a neural network system for stimulus-driven visual attention [1], which has the ability to track moving objects. In this context, stimulus-driven means, that the network attends to a location by evaluating information as single events fed to the network from the visual scene captured by a Dynamic Vision Sensor (DVS) sensor. A single DVS pixel (receptor) can generate events in response to a change of detected illumination. Events encode dynamic features of the scene, e.g. moving objects, using a spatio-temporal set of events. The neural network should stay focused on the target and neglecting all sources of noise, even if the noise is more salient than the target itself or if the target is starting to move. The network will implement a representation of the visual world in which items, objects or locations are represented by neural activity that is proportional to an attentional priority, called saliency map. Practically, the works assumes the development of a neural network and its use in a real-time setup when data from an event-base DVS camera is fed to the network.
Tasks
- Get familiar with the DVS sensor and its programming model.
- Investigate existing models for visual attention and their technical implementations.
- Design and implement a neural network based algorithm to implement visual attention.
- Design experiment for testing and evaluating the implementation using the DVS sensor data as input to the neural network.
Required skills
Strong programming experience (C++, Python), good mathematical skills, machine vision.
Preferred field of study
BA/MA Computer Science, BA/MA Electrotechnics, BA/MA Mechatronics
Contact person
Prof. Thomas Grauschopf – thomas.grauschopf@thi.de
Dr. Cristian Axenie – axenie@thi.de
Bibliography
[1] Nicolas P. Rougier. Emergence of attention within a neural population. Neural Networks 19, 2005.
Saliency Maps Algorithms for Object Detection
Problem description
Humans move their eye to sample in detail the most relevant features of a scene, while spending only limited processing resources elsewhere. The ability to predict, given an image (or video), where a human might fixate in a fixed-time free viewing scenario has long been of interest in the machine vision community. This process of consistently fixating on “important” or salient information, brings great advantages in compression and recognition applications, such as those related to autonomous driving. The leading models of visual saliency may be organized into three stages: 1) extraction: extract feature vectors at locations over the image plane; 2) activation: form an “activation map” (or maps) using the feature vectors; and 3) normalization/combination: normalize the activation map (or maps, followed by a combination of the maps into a single map). The project proposes the implementation of a bottom-up saliency model based on graph computations, called Graph-Based Visual Saliency (GBVS) [1]. The implementation should be both available for RGB images and videos.
Tasks
- Get familiar with the saliency model in [1].
- Investigate other existing models for saliency maps, such as [2].
- Design and implement the model in [1] for single image and video.
- Design and implement the model in [2] for single image and video.
- Design experiment for testing and evaluating the implementation of model [1] against the model in [2].
Required skills
Strong programming experience (C++, Python), good mathematical skills, machine vision.
Preferred field of study
BA/MA Computer Science, BA/MA Electrotechnics, BA/MA Mechatronics
Contact person
Prof. Thomas Grauschopf – thomas.grauschopf@thi.de
Dr. Cristian Axenie – axenie@thi.de
Bibliography
[1] J. Harel, C. Koch, and P. Perona, “Graph-Based Visual Saliency”, Proceedings of Neural Information Processing Systems (NIPS), 2006.
[2] L. Itti, C. Koch and E. Niebur, “A model of saliency-based visual attention for rapid scene analysis,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 20, no. 11, pp. 1254-1259, Nov. 1998.
Event-based Vision for End-to-end VR Avatar Reconstruction
Full PDF description
Problem description
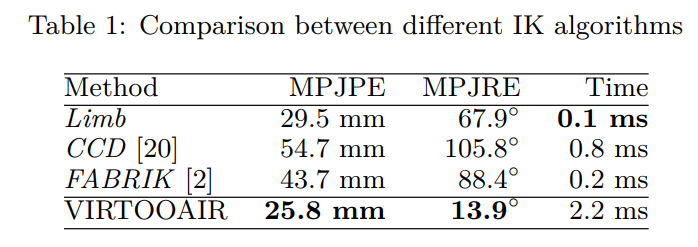
The proposed project explores the capability of using a novel vision sensor (i.e. event-based/frameless camera) for VIRTOOAIR: Virtual Reality Toolbox for Avatar Intelligent Reconstruction. VIRTOOAIR focuses on designing and developing a Deep Learning framework for improved avatar representations in immersive collaborative virtual environments. There have been substantial efforts in designing end-to-end frameworks for reconstructing a full 3D mesh of a human body from a single RGB image. However, these solutions all need to: a) construct or learn a camera model, b) have available keypoints information, and c) segment / pre-process RGB data in order to extract the kinematics of the body in the field-of-view. Typical approaches offer a rich and complex representation of such quantities, with the price of increase latency. We propose the use of a novel camera type as input to an end-to-end reconstruction framework, namely a Dynamic Vision Sensor (DVS), which will allow the system to “go away from frames”. Similar to photoreceptors in the human retina, a single DVS pixel (receptor) can generate events in response to a change of detected illumination. Events encode dynamic features of the scene, e.g. moving objects, using a spatio-temporal set of events. Since DVS sensors drastically reduce redundant pixels (e.g. static background features) and encode objects in a frameless fashion with high temporal resolution (about 1 μs), it is well suited for fast motion analyses and tracking. Such an input can be used to replace the RGB input used in the VIRTOOAIR end-to-end infrastructure. The goal is to explore, how such low-latency input can improve the overall response time of the end-to-end reconstruction.
Tasks
- Get familiar with the DVS sensor and its programming model.
- Investigate the design and usage of the existing VIRTOOAIR end-to-end reconstruction framework and existing code base.
- Design and implement a novel algorithm to interface the event-based data with the end-to-end reconstruction framework.
- Design experiment for testing and evaluating the implementation versus the RGB implementation (i.e. latency, accuracy).
Required skills
Strong programming experience (Python), good mathematical skills, machine vision experience.
Preferred field of study
BA/MA Computer Science, BA/MA Mechatronics (Robotics)
Contact person
Prof. Thomas Grauschopf – thomas.grauschopf@thi.de
Dr. Cristian Axenie – axenie@thi.de
Deep Learning Networks for Efficient Learning in VR Avatar Reconstruction
Full PDF description
Problem description
The projects proposes the exploration and evaluation of Deep Residual Learning for Image Recognition for the end-to-end reconstruction framework in VIRTOOAIR: Virtual Reality Toolbox for
Avatar Intelligent Reconstruction. VIRTOOAIR focuses on designing and developing a Deep Learning framework for improved avatar representations in immersive collaborative virtual environments. Deeper neural networks are more difficult to train. ResNet is a novel deep learning architecture capable of explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. Empirical experiments shown that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. Such a network is used in the end-to-end reconstruction framework for converting the encoded RGB image from a camera into a position vector. In other words, an image I is passed through a convolutional encoder. This is sent to an iterative 3D regression module that infers the latent 3D representation of the human that minimizes the joint re-projection error. The project aims at exploring ResNet architectures and re-implement the regression module in the end-to-end framework to also consider data from the VR controllers (i.e. 2 hand controllers and 1 head controller). The VR controllers are the main components for the VR systems. They interact with the system’s processing unit which computes the orientation of the user’s view point, from hand and head devices.
Tasks
- Get familiar with VIRTOOAIR deep learning end-to-end reconstruction framework and existing code base.
- Investigate the design and usage of the existing VIRTOOAIR ResNet neural networks in the regression module for pose, shape and camera parameters estimation.
- Design and develop a novel position calibration using VR controllers’ data using deep artificial neural networks.
- Design and implement the ResNet to combine image data with VR Controllers data and apply it in real-time in the end-to-end reconstruction framework.
- Design experiment for testing and evaluating the implementation (i.e. latency, accuracy).
Required skills
Strong programming experience, good mathematical skills, machine learning and algorithms.
Preferred field of study
BA/MA Computer Science, BA/MA Mechatronics(Robotics)
Contact person:
Prof. Thomas Grauschopf – thomas.grauschopf@thi.de
Dr. Cristian Axenie – axenie@thi.de
Sensor Fusion for Improved VR Avatar Pose Estimation
Full PDF description
Problem description
The proposed project proposes the development of a sensor fusion method for VIRTOOAIR: Virtual Reality Toolbox for Avatar Intelligent Reconstruction. VIRTOOAIR focuses on designing and developing a Deep Learning framework for improved avatar representations in immersive collaborative virtual environments. The specific sensor fusion problem proposes improved position estimation from single RGB frames acquired from a camera (i.e. estimated through a deep learning network) and VR controllers. The VR controllers are the main components for the VR systems. They interact with the system’s processing unit which computes the orientation of the user’s view point, from hand and head devices. Yet, it is not straightforward to calculate the position of the user using the information from the controllers. We developed an inverse kinematics solver which can convert the data from the controllers into motion angles using a neural network. Similarly, using a deep neural network we can also extract position information from the incoming RGB frames from the camera. This project aims at exploring algorithms for fusing RGB estimated pose and the inverse kinematics estimated pose from the VR controllers.
Tasks
- Get familiar with VIRTOOAIR deep learning end-to-end reconstruction framework and existing code base.
- Investigate the design and usage of the existing VIRTOOAIR neural networks inverse kinematics solver using controllers’ data.
- Get familiar with typical sensor fusion algorithms (e.g. Kalman Filter, Complementary Filters, and Bayesian Inference).
- Design and implement the selected algorithms and apply them in real-time in the end-to-end reconstruction framework.
- Design experiment for testing and evaluating the implementations (i.e. latency, accuracy).
Required skills
Strong programming experience (Python), good mathematical skills, machine vision experience.
Preferred field of study
BA/MA Computer Science, BA/MA Mechatronics (Robotics)
Contact person
Prof. Thomas Grauschopf – thomas.grauschopf@thi.de
Dr. Cristian Axenie – axenie@thi.de
Multimodal Avatar Augmentation using Event-based and Depth Cameras
Full PDF description
Problem description
Remote VR has enormous potential to allow physically separated users to collaborate in an immersive virtual environment. These users and their actions are represented by avatars in the virtual environment. It has been shown that the appearance of those avatars influences interaction. Moreover, a one-to-one mapping of the user’s movements to the avatar’s movements might have advantages compared to pre-defined avatar animations. In this context, the project proposes a multimodal augmentation of typical avatars (i.e. built using head and hand controller tracking). Using new modalities (i.e. event based vision and depth sensors) the avatar augmentation can be two fold: motion can be improved by having faster motion detection and estimates from the event-based camera; localization can me improved by calculating distance to objects using depth information. The event-based camera (Dynamic Vision Sensor – DVS) is a novel technology in which each pixel individually and asynchronously detects changes in the perceived illumination and fires pixel location events when the change exceeds a certain threshold. Thus events are mainly generated at salient image features like edges which are for example due to geometry or texture edges. The depth information is obtained from an active depth-sensing camera sensor (e.g. Kinect, ASUS Xtion, Primesense). The combination of the two results in a sparse stream of 3D point events in camera coordinates which directly give the 3D position of salient edges in the 3D scene. The combination of DVS and depth sensors is a promising opportunity for a new type of visual processing by using a sparse stream of 3D points events which captures only dynamic and salient information invaluable for having precise avatar construction.
Tasks
- Get familiar with the DVS and depth sensor.
- Investigate depth sensor technologies (i.e. resolution, detection, interfacing).
- Program an interface to acquire data from DVS and depth sensor.
- Program a fusion mechanism for data from DVS and depth sensor.
- Program an interface from DVS and depth sensor to VR system.
Technology
DVS
http://xtionprolive.com/primesense-carmine-1.0
Required skills
Strong programming experience, computer vision and algorithms.
Preferred field of study
BA/MA Mechatronics(Robotics), BA/MA Computer Science
OLD TOPICS
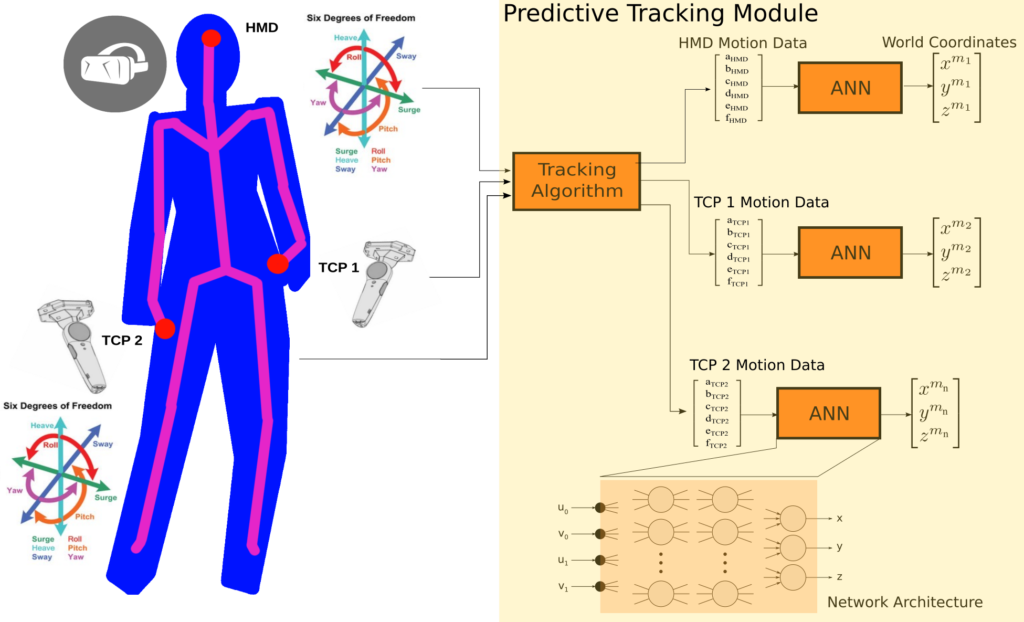
Neural Network Predictive Tracking System for VR Systems
Full PDF description
Problem description
The tracking devices are the main components for the VR systems. They interact with the system’s processing unit which computes the orientation of the user’s view point. Solutions for full-body tracking / motion capturing need a lot of cameras and are therefore expensive. Furthermore, the calibration process prior to usage is not trivial and highly time consuming. The tracking data are updated with a certain frequency and to ensure smooth movements prediction is crucial. Despite the multitude of algorithms for such a predictive tracking scenario, the performance is dictated by the underlying tracking system’s sampling rate and the noise and variance in the captured data. Moreover the types of motion that the user performs, being head or hand (controller) play an important role in determining which algorithm to use. The project proposes a neural network approach for predictive tracking. Such a neural network predictive tracker learns a generic relationship between motion and appearance. This approach doesn’t need to develop a complex mathematical model of the problem, i.e. the projection of 18D body motion coordinates (three translational coordinates which define the position and three rotational coordinates which define the orientation for each of the head and hand VR controllers) to 3D world coordinates. The mapping is performed by the neural network which behaves like a universal function approximator.
Tasks
- Program a data acquisition interface for logging the 18 degrees of freedom (DOF) as input from the VR controllers tracking system. These are six DOFs for the head and each of the hands.
- Investigate the design of deep neural networks for regression in multidimensional problems.
- Design and develop a novel position calibration using VR controllers data using deep artificial neural networks.
- Design a prediction model which uses the neural network calibration for tracking.
- Test and evaluate the learnt mapping against ground truth (i.e. camera tracking system).
Required skills
Strong programming experience, good mathematical skills, basic VR technologies, machine learning and algorithms.
Preferred field of study
BA/MA Computer Science, BA/MA Mechatronics(Robotics)
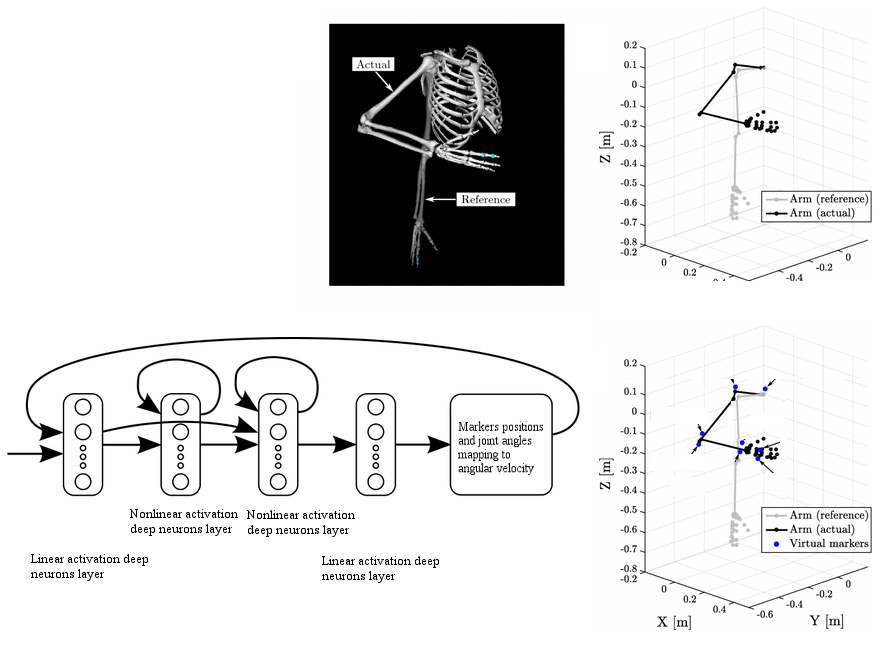
Learning Inverse Kinematics for VR Avatars
Full PDF description
Problem description
In VR systems head and hands controllers are critical for motion estimation in reliable avatar construction. Inverse kinematics calculations offer the possibility to calculate poses for arm joints and upper body out of controllers’ positions. This data could be used for an improved avatar display. The problem of learning of inverse kinematics in VR avatars interactions is useful when the kinematics of the head or controllers are not accurately available, when Cartesian information is not available from camera coordinates, or when the computation complexity of analytical solutions becomes too high. The major obstacle in learning inverse kinematics is the fact that this representation has an infinite solution space. Thus the learning algorithm has to converge to a particular inverse and to make sure that this inverse is a valid solution. The project proposes a neural network learning approach for leaning the inverse kinematics mapping (i.e. the Jacobian). For the task of learning such a non-linear mapping among the combined position and joint angles to changes in joint angles (i.e. angular velocities) we investigate the use of a multi-layer deep neural network with a dedicated architecture capable of avoid kinematic singularities, using tracking data, which is always physically correct and will not demand impossible postures as can result from an ill-conditioned matrix inversion.
Tasks
- Investigate the basics of inverse kinematics calculation in VR systems.
- Investigate neural networks capabilities for function approximations.
- Design and implement a neural network learning system for Jacobian estimation.
- Test and evaluate the learnt mapping against ground truth (i.e. camera tracking system).
Required skills
Strong programming experience, mechanics and kinematics knowledge, basic VR technologies, machine learning and algorithms.
Preferred field of study
BA/MA Computer Science, BA/MA Mechatronics(Robotics)
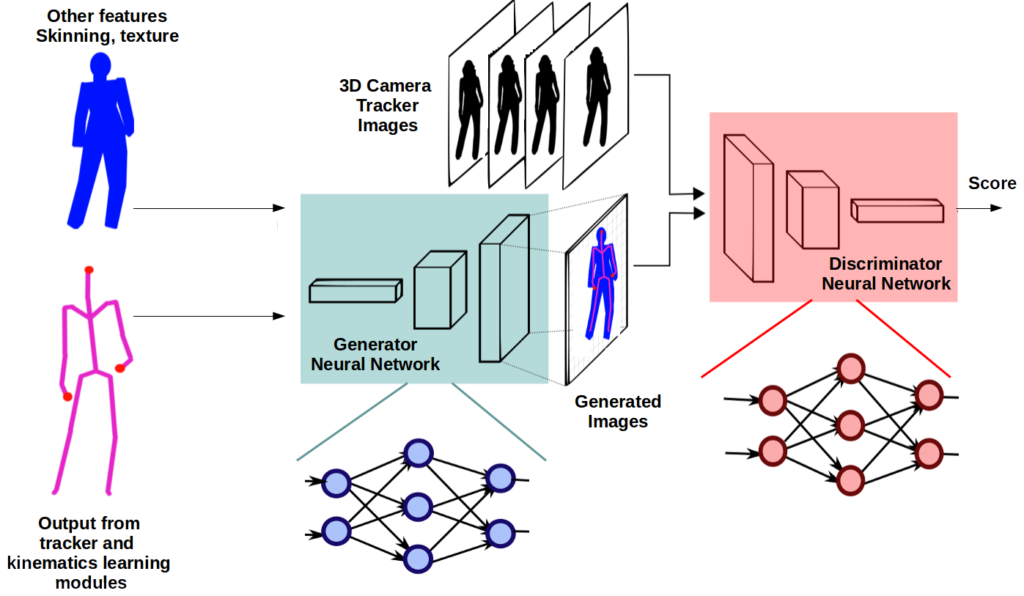
Neural Network Avatar Reconstruction in Remote VR Systems
Full PDF description
Problem description
In collaborative VR scenarios with remote sites, data must be transferred through network. The amount of data is therefore limited by the given bandwidth. Also, the data transfer is prone to network latency which is induced by a variety of factors like signal speed and time processing / buffering in network nodes. The larger the amount of data to transfer, the larger is the liability to network congestion which induces additional latency. Therefore, it is preferable to limit the amount of transferred data as far as possible. An approach capable to overcome such problems is compressive sensing, which can use deep learning through the capability to represent many signals using a few coefficients in a suitable representation. The project proposes the development of a system capable of learning the inverse transformation (i.e. generating an image out of tracking data) from measurement vectors to signals using a neural network. Such an approach will allow learning both a representation for the signals / data being transmitted and an inverse mapping approximating a recovery. Deep Networks are a good candidate for such a task, and especially Generative Adversarial Networks (GAN) have been shown to be quite adept at synthesizing novel data based on training samples, especially from noisy and small amounts of data. Such a network is forced to efficiently represent the training data, making it more effective at generating data similar to the training data. The system will be employed both locally and remotely in the avatar reconstruction to allow the rendering to be more accurate.
Tasks
- Study the basics of data bandwidth impact on remote VR avatar reconstruction.
- Investigate deep neural networks for data compression and recovery.
- Design and implement a neural network learning system using GAN.
- Test and evaluate the data reconstruction against ground truth (i.e. camera tracking system).
Required skills
Strong programming experience, machine learning and algorithms, signal processing.
Preferred field of study
BA/MA Computer Science, BA/MA Mechatronics(Robotics)