


ENVISAS: Event-based Neuromorphic VISion for ASsistive Devices
Context
According to a study from the year 2010, about 39 million people are blind. These people are not able to perceive depth. To help this population to perceive their surroundings better, assistive medical devices were designed. With modern technologies and computing power, better solutions could be provided. If a medical device can provide a depth representation of the surrounding world in form of a depth map, this map can be used to transform the depth data into a multisensory (i.e audio, haptic) representation of the depth.
Goal
Event cameras use bio-inspired sensors that differ from conventional frame-based camera sensors: instead of capturing images at a fixed rate, they asynchronously measure per-pixel brightness changes and output a stream of events that encode the time, location, and polarity (i.e. on/off) of the brightness changes. Novel methods are required to process the unconventional output of these sensors in order to unlock their potential. Depth estimation with a single event-based camera is a significantly different problem because the temporal correlation between events across multiple image planes cannot be exploited. Typical methods recover a semi-dense 3D reconstruction of the scene (i.e., 3D edge map) by integrating information from the events of a moving camera over time, and therefore require knowledge of camera motion. Recently, learning-based approaches have been applied to event-based data, thus unlocking their potential and making significant progress in a variety of tasks, such as monocular depth prediction. This way, one can benefit from an efficient visual perception of the scene for fast extraction of depth in assistive devices.
Current stage
Toolset and Benchmark Framework for Monocular Event-based Depth Extraction
The project addresses the problem of monocular depth extraction in a comparative setup between traditional (frame-based) cameras and novel event-based cameras. The core goal of the project is the design and implementation of a test rig, a software framework for benchmarking algorithms, together with their calibration and validation. This first project sets the ground for upcoming research aiming at evaluating which is the best configuration of camera type and algorithm for monocular depth extraction for assistive devices.
The test rig developed in the initial project combined a dynamics vision sensor (event-based camera) and a Kinect sensor.

The GUI allows the developer to choose the algorithm, parametrize, calibrate, validate it and load/save data.
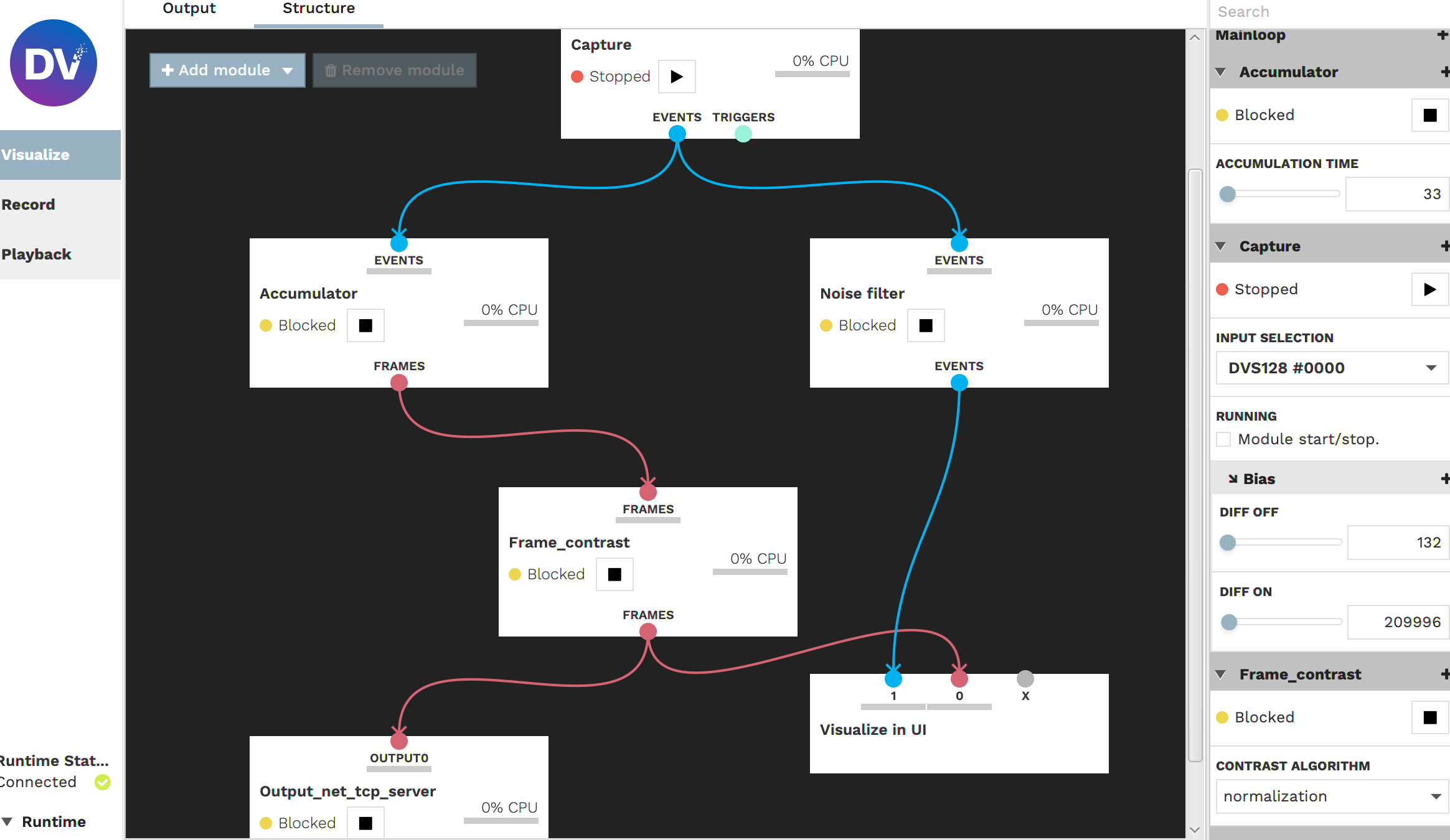
The benchmark framework data ingestion, processing, and evaluation pipeline overview.
